



(tl;dr - scroll down and look at the pretty pictures !)
Object relational mappers give us a way to automate the translation of domain model concepts into SQL and relational database concepts. The SQLAlchemy ORM's level of automation is fairly high, in that it tracks changes in state along a domain model to determine the appropriate set of data to be persisted and when it should occur, synchronizes changes in state from the database back to the domain model along transaction boundaries, and handles the persistence and in-memory restoration of entity relationships and collections, represented as inter-table and inter-row dependencies on the database side. It also can interpret domain-specific concepts into SQL queries that take great advantage of the relational nature of the backend (which in non-hand-wavy speak generally means, SQLAlchemy is fairly sophisticated in the realm of generating joins, subqueries, and combinations thereof).
These are complex, time consuming tasks, especially in an interpreted language like Python. But we use them for the advantage that we can work with fully realized relational models, mapped to domain models that match our way of looking at the problem, with little to no persistence-specific code required outside of configuration. We can optimize the behavior of persistence and loading with little to no changes needed to business or application logic. We save potentially dozens of lines of semi-boilerplate code that would otherwise be needed within each use case to handle the details of loading data, optimizing the loads as needed, marshalling data to and from the domain model, and persisting changes in state from domain to database in the correct order. When we don't need to code persistence details in each use case, there's less code overall, as well as a lower burden of coverage, testing, and maintenance.
The functionality of the ORM is above and beyond what we gain from a so-called "data abstraction layer". The data abstraction layer provides a system of representing SQL statements, bound values, statement execution, and result sets in a way that is agnostic of database backend as well as DBAPI. A data abstraction layer may also automate supplementary tasks such as dealing with primary key generation and sequence usage, generation and introspection of database schemas, management of functions that vary across backends such as savepoints, two phase transactions, complex datatypes.
The data access layer is of course critical, as an ORM cannot exist without one. SQLAlchemy's own data abstraction system forms the basis of the object relational mapper. But the distinction between the two is so critical that we have always kept the two systems completely separate - in our current documentation the systems are known as SQLAlchemy Core and SQLAlchemy ORM.
Keeping these systems explicitly separate helps the developer be aware of a conscious choice - which is that he or she is deciding that the higher level, but decidedly more expensive automation of the ORM layer is worth it. It's always an option to drop down into direct activity with the data abstraction layer, where the work of deciding what SQL statements to create, how they are constructed, when to execute them, and what to do with their results are up to the developer, but the in-Python overhead is fixed and relatively small. Lots of developers forego the ORM entirely for either performance or preferential reasons, and some developers build their own simple object layers on top of the data abstraction layer.
In my own case, my current project involves finance and the ability to persist sets of data across two dozen tables along the order of 500K rows per dataset (where the "dataset" is a set of analytics and historical information generated daily), loading them back later to generate reports, with heavy emphasis on Decimal formatting and calculations. As my project managers suddenly started handing me test files that consisted not of the few hundred records we tested with but more along the order of 20000-30000 records (where each record in turn requires about 20 rows, hence 500K), rewriting some of the ORM code to use direct data abtraction in those places where we need to blaze through all the records seemed like it might be necessary. But each component that's rewritten using the SQL Expression Language directly would grow in size as explicit persistence logic is added, requiring more tests to ensure correct database interaction, reducing reusability, and increasing maintenance load. It would also mean large chunks of existing domain logic, consisting of business rules and calculations that are shared among many components, would have to be refactored in some way to support the receipt and mutation of simple named-tuple result rows (or something similarly rudimentary, else overhead goes right up again), as well as working as they do now associated with rich domain objects. It would most likely add a large chunk of nuts-and-bolts code to what is already a large application with lots of source files, source that is trying very hard to stick to business rules and away from tinkering.
We'd like to delay having to rewrite intricate sections of batch loading and reporting code into hand-tailored SQL operations for as long as possible. This is a new application still under development; if certain components have been running for months or years without any real changes, the burden of rewriting them as inlined SQL is less than when it is during early development, when rules are changing almost daily and the shape of the data is still a moving target.
So to buy us some time, SQLAlchemy 0.7, like all major releases, gets another boost of performance tuning. This tuning is always the same thing - use profiling to identify high-percentage areas for certain operations, remove any obvious inefficiencies within method bodies, then find ways to reduce callcounts and inline functionality into fewer calls. It's very rare these days for there to be any large bottlenecks with "obvious" solutions - we've been cutting down on overhead for years while maintaining our fairly extensive behavioral contract. The overhead comes from just having a large number of pieces that coordinate to execute operations. Each piece, in most cases, is small and gets its work done using the best Python idioms money can buy. It's the sheer number of components, combined with the plainly crushing overhead each function call in Python produces, that add up to slowness. If we do things the way a tool like Hibernate does them, that is using deep call stacks that abstract each decision into its own method, each of those decisions in turn stowing each of its sub-decisions into more methods, building a huge chain of polymorphic nesting for each column written or read, we'd grind to a halt (note that this is fine for Hibernate since Java has unbelievably fast method invocation).
Enter RunSnakeRun
This time around I dove right into a tool that's new to me which one of our users mentioned on the list. It's a graphical tool called RunSnakeRun. Using it this weekend I was able to identify some more areas that were worth optimizing, as well as to get some better insight on the best way for them to be optimized. In addition to the usual dozens of small inlinings of Python code, cleanups of small crufty sections, I identified and caught two big fish with this one:
- The ongoing work with our unit of work code has finally made it possible to batch together INSERT statements into executemany() calls without unreasonable complexity, if certain conditions are met. This was revealed after noticing psycopg2's own execute() call taking up nearly 40% of the flush process for certain large insert operations, operations where we didn't need to fetch back a newly generated primary key, which is usually the reason we can't use executemany().
- The fetch of an unloaded many-to-one relationship from the identity map was incurring much larger overhead than expected; this because the overhead of building up a Query object just so that it could do a get() without emitting any SQL became significant after fetching many thousands of objects.
For a little view into what RunSnakeRun can provide, we will illustrate what it shows us for three major versions of SQLAlchemy, given the profiling output of a small test program that illustrates a fairly ordinary model and series of steps against 11,000 objects. Secretly, these particular steps have been carefully tailored to highlight the improvements to their maximum effect.
The code below should be familiar to anyone who uses the SQLAlchemy ORM regularly (and for those who don't, we have a great tutorial!). The model is innocuous enough, using joined table inheritance to represent two classes of Employee in three tables. Here, a Grunt references a Boss via many-to-one:
from sqlalchemy import Column, Integer, create_engine, ForeignKey, \ String, Numeric from sqlalchemy.orm import relationship, Session from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class Employee(Base): __tablename__ = 'employee' id = Column(Integer, primary_key=True) name = Column(String(100), nullable=False) type = Column(String(50), nullable=False) __mapper_args__ = {'polymorphic_on':type} class Boss(Employee): __tablename__ = 'boss' id = Column(Integer, ForeignKey('employee.id'), primary_key=True) golf_average = Column(Numeric) __mapper_args__ = {'polymorphic_identity':'boss'} class Grunt(Employee): __tablename__ = 'grunt' id = Column(Integer, ForeignKey('employee.id'), primary_key=True) savings = Column(Numeric) employer_id = Column(Integer, ForeignKey('boss.id')) employer = relationship("Boss", backref="employees", primaryjoin=Boss.id==employer_id) __mapper_args__ = {'polymorphic_identity':'grunt'}
We create 1000 Boss objects and 10000 Grunt objects, linking them together in such a way that results in the "batching" of flushes, each of 100 Grunt objects. This is much like a real world bulk operation where the data being generated is derived from data already present in the database, so installing 10000 objects involves a continuous stream of SELECTs and INSERTs, rather than just a big mass execute of 20000 rows:
sess = Session(engine) # create 1000 Boss objects. bosses = [ Boss( name="Boss %d" % i, golf_average=Decimal(random.randint(40, 150)) ) for i in xrange(1000) ] sess.add_all(bosses) # create 10000 Grunt objects. grunts = [ Grunt( name="Grunt %d" % i, savings=Decimal(random.randint(5000000, 15000000) / 100) ) for i in xrange(10000) ] # associate grunts with bosses, persist 1000 at a time while grunts: boss = sess.query(Boss).\ filter_by(name="Boss %d" % (101 - len(grunts) / 100)).\ first() for grunt in grunts[0:100]: grunt.employer = boss grunts = grunts[100:] sess.commit()
We'll illustrate loading back data on our grunts as well as their bosses into a "report":
report = [] for grunt in sess.query(Grunt): report.append(( grunt.name, grunt.savings, grunt.employer.name, grunt.employer.golf_average ))
The above model is more intricate than it might appear, due to the double dependency the grunt table has to both the employee and boss tables, the dependency of boss to employee, and the in-Python dependency of the Employee class to itself in the case of Grunt-> Boss.
With RunSnakeRun, the main part of the display shows us a graphical view of method calls as boxes, sized roughly according to their proportion of the operation. The boxes in turn contain sub-boxes representing their callees. A method that is called by more than one caller appears in multiple locations. With this system, our picture-oriented brains are led by the nose to the "big shiny colors!" that represent where we need to point our editors and re-evaluate how something is doing what it does.
SQLAlchemy 0.5
SQLAlchemy 0.5.8 was a vast improvement both usage- and performance- wise over its less mature predecessors. I would say that it represented the beginning of the third "era" of SQLAlchemy, the first being "hey look at this new idea!", the second being "crap, we have to make this thing work for real!". I'd characterize the third, current era as "open for business". Here, RunSnakeRun shows us the most intricate graph of all three, corresponding to the fact that SQLA 0.5, for all its huge improvements over 0.4, still requires a large number of prominent "things to do" in order to get the job done (where each box that's roughly 1/10th the size of the whole image is a particular bucket of "some major thing we do"):
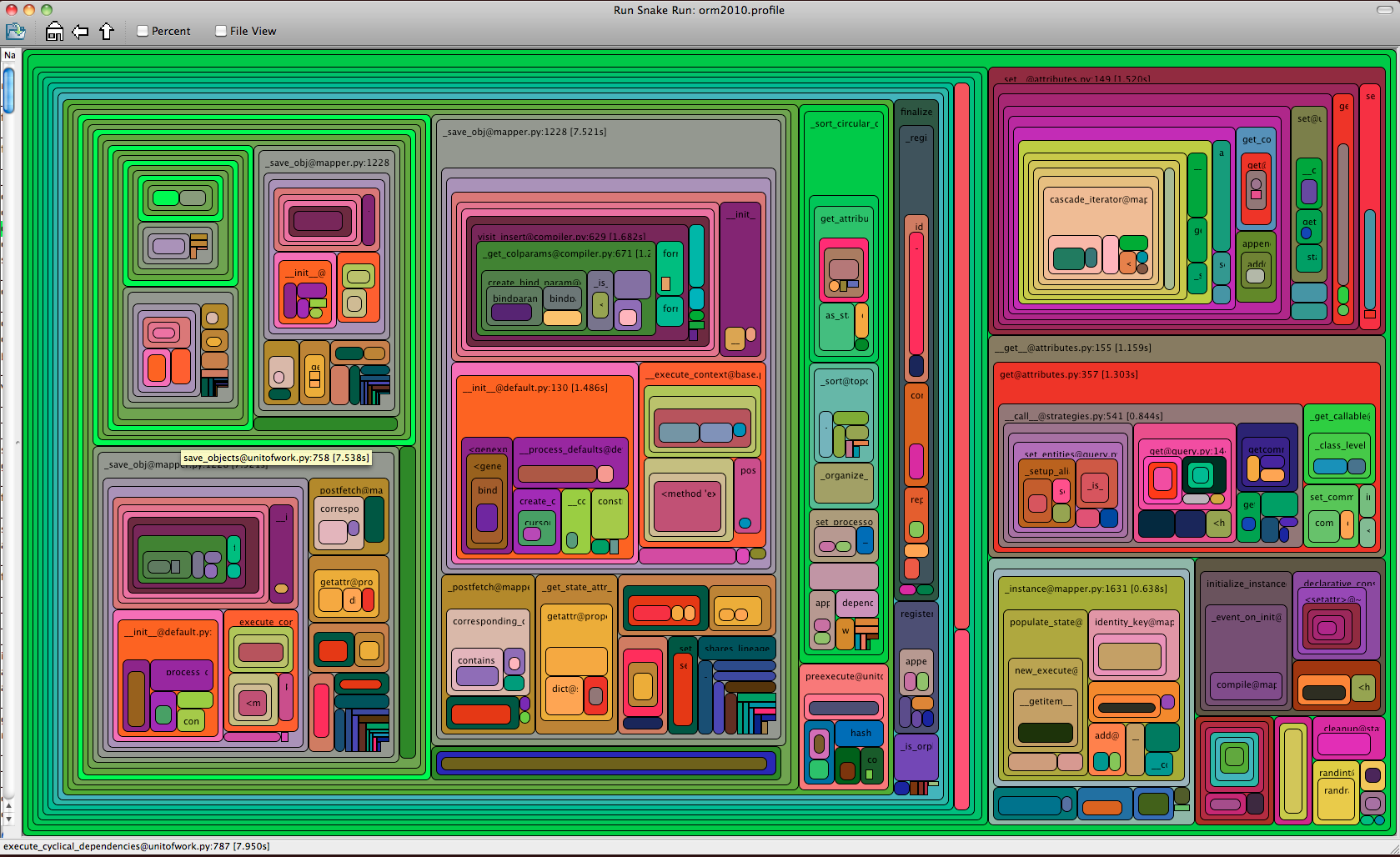
SQLAlchemy 0.5.8
- Total calls: 10,556,480
- Total cpu seconds: 13.79
- Total execute/executemany calls: 22,201
SQLAlchemy 0.6
SQLAlchemy 0.6 featured lots more performance improvements, and most notably a total rewrite of the unit of work, which previously was the biggest dinosaur still lying around from the early days. Here we see a 30% improvement in method overhead. There's a smaller number of "big" boxes, and each box has fewer "boxes" inside each one. This represents less complexity of operation in order to accomplish the same thing:
SQLAlchemy 0.6.6
- Total calls: 7,963,214
- Total cpu seconds: 10.50
- Total execute/executemany calls: 22,201
SQLAlchemy 0.7
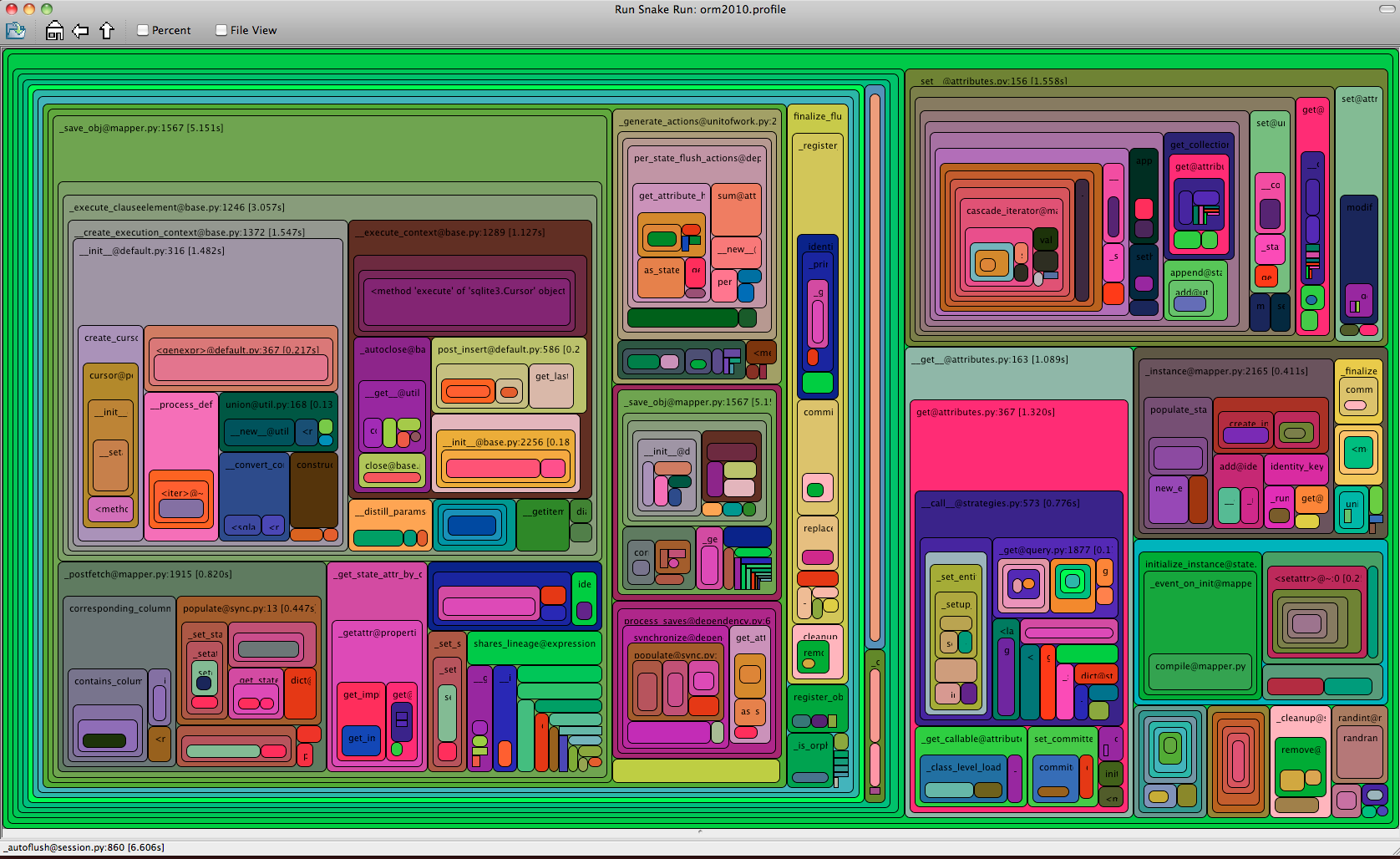
Finally, with 0.7, the fruits of many more performance improvements within the ORM and SQL execution/expression layers, including the two big ones discussed here, illustrate themselves as even bigger fields with fewer, larger boxes inside each one. Function call overhead here (updated 12/22/2010) is around 50% less than 0.6, 62% less than 0.5, and here we also see a reduction in counts to the DBAPI's execute() and executemany() calls by 50%, using the DBAPIs native capability to emit large numbers of statements efficiently via executemany(). Perhaps I've been staring at colored boxes all weekend for too long, but the difference between 0.5, 0.6, 0.7 seems to me pretty dramatic:

SQLAlchemy 0.7.0 (updated 12/22/2010)
- Total calls 3,984,550
- Total cpu seconds: 5.99
- Total execute/executemany calls: 11,302
So I'd like to give props to RunSnakeRun for giving SQLAlchemy's profiling a good shot in the arm. The continuous refactoring and refinements to SQLA are an ongoing process. More is to come within SQLAlchemy 0.7, which is nearly ready for beta releases. Look for larger and fewer colored boxes as we move to 0.8, 0.9, and...whatever comes after 0.9.
Source code, includes more specifics and annotations related to the test as well as changes in SQLAlchemy versions for this particular kind of model.