


We're revisiting Robert Brewer's Storm, SQLAlchemy and Geniusql. In that post, Robert set up a series of test suites intended to exercise the execution of basic INSERT, UPDATE and SELECT statements, using the established paradigms of each toolkit. For SQLAlchemy, he used SQLAlchemy's SQL expression language and not its ORM, Geniusql's expression language, and mostly Storm's ORM except for one or two tests. The article observes poor performance mostly on the part of SQLAlchemy compared to the other two, and spends lots of time poking at SQLAlchemy stack traces, making various guesses on why we're so slow, and issuing various somewhat damning comments about SA's design. SQLAlchemy responded immediately with some commentary as well as a new round of speed enhancements in response to some of the "cleanup" items Robert mentioned; but we only focused on SQLAlchemy - we didn't get around to digging deeper into each individual platform's tests and behavior to see what really made them different. In this post, we've finally done that, and the results are very enlightening.
Robert's results have always seemed strange to SQLAlchemy users since they implied a SQLAlchemy that was almost unusably bloated, which is not observed in the real world. Robert is an experienced developer so I didn't have much doubt, as I'm sure others didn't either, that he was careful in constructing his tests and ensuring that they were working as expected. As a result, SQLAlchemy spent a lot of focus on the SA tests, trying to analyze places where we might be able to become faster. Nobody, as far as I know, spent any time looking at the other two tests to see why they might be so fast, particularly in the case of Storm where even its ORM, which by definition should be slower than direct SQL constructs, seemed considerably faster than SA's lower level SQL construction language...and curiously, that of Geniusql as well.
It turns out that with just a few minor corrections, even SQLAlchemy's previous 0.3 series comes in second place, slightly slower than Geniusql and usually faster than Storm's ORM (remember that the SQLAlchemy tests are against the lower-level expression language, so they should be faster than an ORM). For all of Robert's detailed critique of SQLAlchemy's execution and analysis of its "slowness", it's hard to imagine that he made sure to check that both Storm as well as his own Geniusql were also doing what was expected; since a brief look at the actual SQL emitted by each test immediately reveals where most of the extra SQLAlchemy time is being spent - in SQL execution which is plainly not occurring (even though assumed to be) in the case of the other two products.
So to set the record straight (better late than never), I've fixed the tests, modified them to run under a common set of fixtures, and fired up the charts and graphs. I've added a fourth suite to the tests, a SQLAlchemy ORM test which almost duplicates the Storm ORM test on a line-by-line basis. The test platform is the MacBook Pro 2.2 Ghz Intel Core Duo, using Python 2.5.1, Postgres 8.2.5, Psycopg2-2.0.6. SQLAlchemy is trunk r3974 (will be release 0.4.2), Storm version 0.11, and Geniusql r248. The actual speed comparisons between these tools are quite boring. How boring ? This boring:
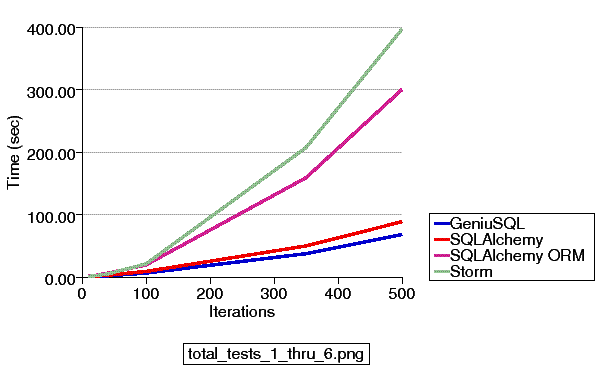
Where above, Storm runs very fast except for test #4, which as it turns out takes up 78% of the suite's total runtime for the two ORMs. The ORMs are generally similar in speed and a brief test of Storm's expression language in test #5 is faster than both SQLAlchemy and Geniusql. Geniusql, which is still alpha and notably does not use any bind parameters, is consistently a little faster than SQLAlchemy EL.
The full test suite and everything else is viewable here. Of note are the unified diffs which compare my version of the tests to Robert's originals, as well as a diff of the Storm ORM test against the new SQLAlchemy ORM test. I've tried to change as little as possible, and the main structural difference is the common benchmark runner.
So what was happening with Robert's tests ? Just two main points:
SQLAlchemy is instructed to issue hundreds of COMMIT statements. Storm is instructed to issue exactly one, Geniusql fails to issue any (even though instructed to).
Robert relied upon SQLAlchemy's "autocommit" feature for all INSERT and UPDATE statements; a COMMIT is issued to the database after every statement. Whereas with Storm, he used the ORM which does not "autocommit", you have to call store.commit() explicitly, which he did not. Additionally, he sets this flag on Geniusql: db.connections.implicit_trans = True, which is meant to instruct Geniusql to issue COMMIT after each INSERT or UPDATE. But at least in the most current SVN revision of Geniusql, this flag does nothing whatsoever; grepping through PG's SQL logs reveals this. So to compensate for the lack of transactions in the other two test suites, changing the SQLAlchemy engine declaration from this:
db = create_engine(uri)
To this:
db = create_engine(uri, strategy="threadlocal") db.begin()
Thus starting a transaction and disabling the COMMIT after each statement, allows the SQLAlchemy SQL expression test, even using the old version 0.3, to hug very closely to Geniusql's. This is why SQLAlchemy seemed so slow in the tests which involved issuing INSERTs and UPDATEs. - the overhead of many hundreds of transaction commits within Postgres is profoundly significant. All the huge amounts of code cleanup and optimizations we've added between 0.3 and the current 0.4 don't approach the time saved by this one small change.
But we're not done yet; another factor was key in the huge graphs posted for test numbers 2 and 3:
Storm tests two and three issued almost no SQL whatsoever.
As surprising as this seems, Robert's graph illustrating Storm supposedly executing hundreds of INSERT statements and SELECT statements at unbelievable speeds actually depicts Storm issuing no INSERT or SQL whatsoever in test #2, and no SELECTs whatsoever in test #3. Let's look:
def step_2_insert(self): for x in xrange(ITERATIONS): store.add(Animal(Species=u'Tick', Name=u'Tick %d' % x, Legs=8))
What's missing there ? Theres no flush() ! Adding a single flush() at the end of the iterations allows the items saved to the store to actually be emitted to the database as INSERT statements:
def step_2_insert(self): for x in xrange(ITERATIONS): store.add(Animal(Species=u'Tick', Name=u'Tick %d' % x, Legs=8)) store.flush()
And suddenly the test performs in a believable amount of time, 0.12 seconds for 100 iterations instead of .015. The reason things seem to "work" without the explicit flush is because Storm issues its 0.12-second flush at the beginning of test #3, so that the data is available for subsequent tests - but because test #3 is meant to take nearly twenty times longer than test #2, this tiny hit at the beginning is unnoticeable, and test #2 gets away with issuing no SQL at all.
For test #3, I have a feeling Robert might have generated his graphs from a more reasonable test, considering that he mentioned using store.find().one(); but as far as what he posted for the actual test, Robert is issuing finds using Storm's ORM, but he's not asserting the results, and he's doing it like this:
WAP = store.find(Zoo, Zoo.Name==u'Wild Animal Park')
As Robert said, "There must be some things that SQLAlchemy is doing that the others are not." Indeed - issuing the expected SELECT statements. The Storm Store, like SQLA's Query, does not evaluate results until called in an iterative context. So fix as follows:
WAP = list(store.find(Zoo, Zoo.Name==u'Wild Animal Park'))
And once again, the miraculous speed of .02 seconds for 800 full SELECT statements becomes a believable 1.4 seconds.
The actual results for test number two are as follows:
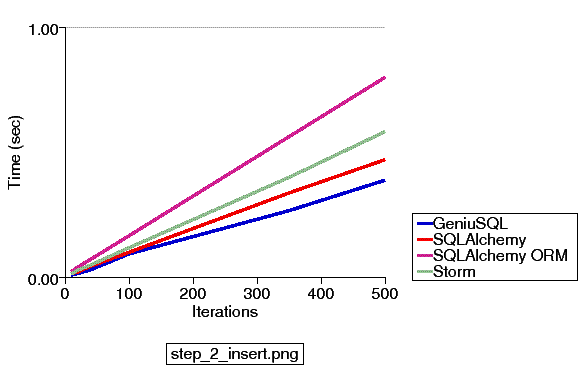
A particular thing to note about test #2 is that we are dealing with a total time of less than one second, even for 500 iterations. Even though you see those four lines diverging, its a horse race around the head of a pin; the differences here are not very important compared to other areas.
For number three:
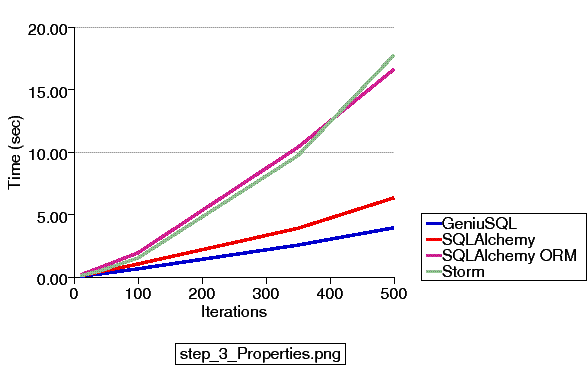
This test takes considerably longer, and SQLAlchemy's ORM and Storm's are performing very similar operations, as are SQLAlchemy's expression constructs and Geniusql's.
Let's look at test #4 again. This test involves a battery of about 21 SELECT statements, fully fetched, repeated for a number of iterations; so 100 iterations would be 2100 SELECT statements and result sets fully fetched.
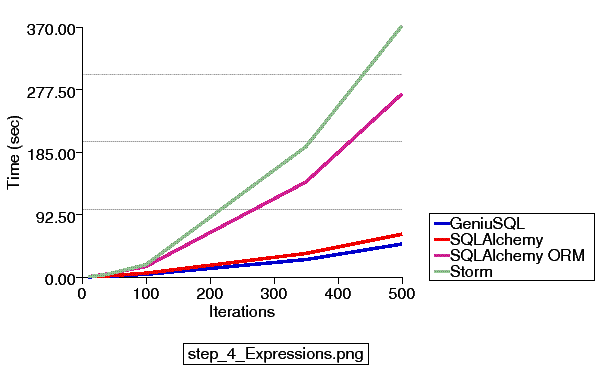
This is the only test where Storm's ORM can possibly increase its efficiency in fetching; however, you can see that SQLAlchemy's ORM needs to perform a similar amount of work as Storm (we've just optimized the crap out of our ORM fetches in recent versions); fetching ORM-mapped objects is a much more complex operation than fetching rows, as the identity of each row needs to be evaluated, a matching already-loaded object must be searched for, and if not found a new object is instantiated and each of its attributes populated. SQLAlchemy's SQL constructs perform similarly to Geniusql, and you can be sure that Storm's SQL constructs are similarly fast.
Test #5, "aggregates", issues four SELECT statements for a number of iterations (i.e. 400 for 100 iterations) using the raw SQL constructs of each platform, ORMs included:
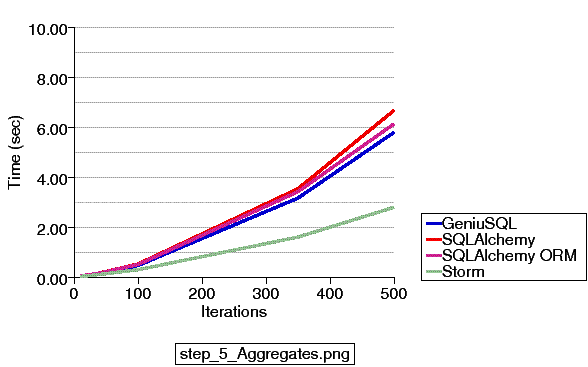
Storm uses fewer method calls for this operation, but it curiously makes more of a difference in just this test than in other tests where it also has fewer calls. On that topic, here's a graph of comparative function callcounts, as reported by hotshot, for one iteration in each test:
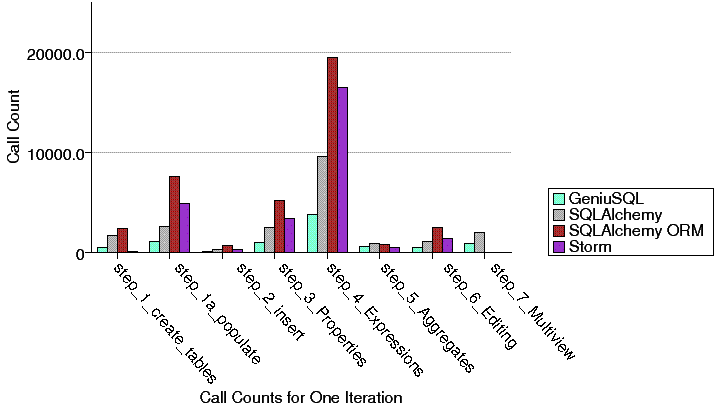
This data falls in line with what we'd expect; SQLAlchemy's ORM is more complex than that of Storm and uses more function calls. The SQL expression language obviously uses less than either ORM in most cases - this graph directly contradicts most of Robert's comments to the effect of "SQLAlchemy (specifically the expression language) is doing much more than the others". Also interesting is that while Geniusql, a very small toolkit only at rev 248, uses less calls than SQLAlchemy's expression language, the ultimate speeds of both turn out to be somewhat similar in all tests (at least, more similar than their callcounts are different), which implies that the time taken on the database side is a significant factor in speed.
Test number six shows competitive results between all products. This test loads a record, changes it, and reselects it, then repeats the process.
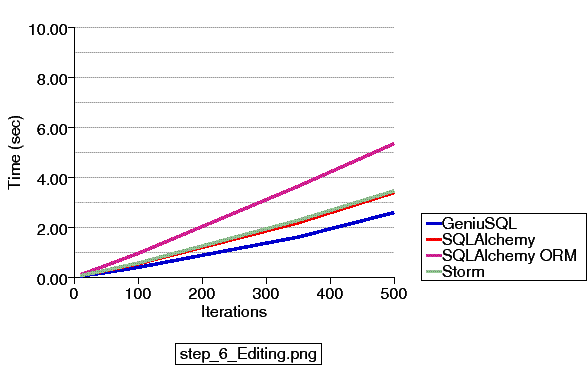
Storm makes usage here of its ability to issue a quick UPDATE statement and invalidate its ORM cache simultaneously. SQLAlchemy EL clocks comparably to Storm's optimized operation, whereas SQLAlchemy ORM needs to fall back on a slightly more expensive flush() to update the record in the database and session simultaneously. To address this, SQLAlchemy will be adding a criterion-based session invalidation feature to its Query object in an upcoming release, possibly 0.4.3.
Robert didn't implement test number seven for the ORM, so the head to head matchup is below. Nothing too interesting here:
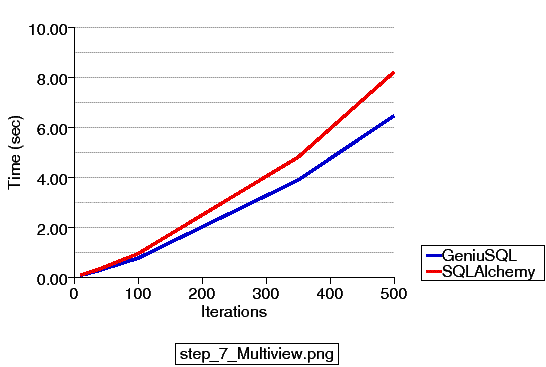
So admittedly six months too late, I'm hoping this illustrates that there are only slight to moderate differences in performance between these products at a Python execution level. Your app won't grind to a halt with SQLAlchemy nor perform miraculous volumes of SQL in mere milliseconds with Storm or Geniusql - the data Robert illustrated as well as his hypotheses to explain those findings are just inaccurate. All the hypothesizing about connection pool slowness and everything else mentioned, while not insignificant, have never created huge performance issues, and we of course continue to optimize and re-simplify all areas of SQLAlchemy on a constant basis (where the "de-simplification" occurs in response to new behaviors and feature improvements which we add all the time). SQLAlchemy maintains that the best way to get the fastest performance from a database application remains to use the most appropriate SQL at the most appropriate times; exactly the reason why SQLAlchemy has a very rich expression language and SQL compiler, and a highly featured and finely-tunable ORM which improves with every release.