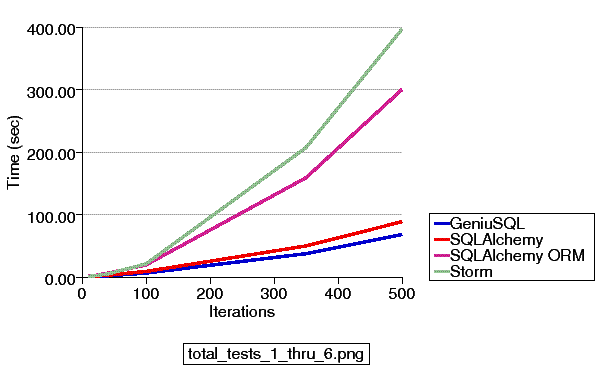
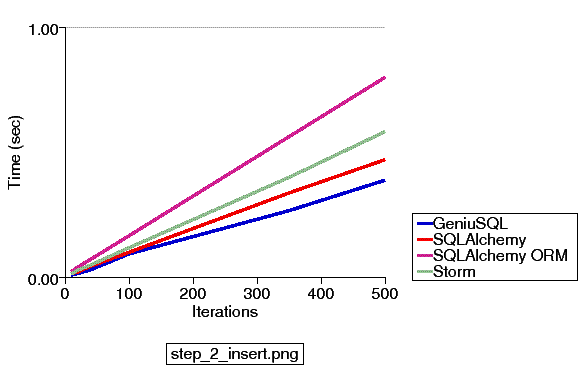
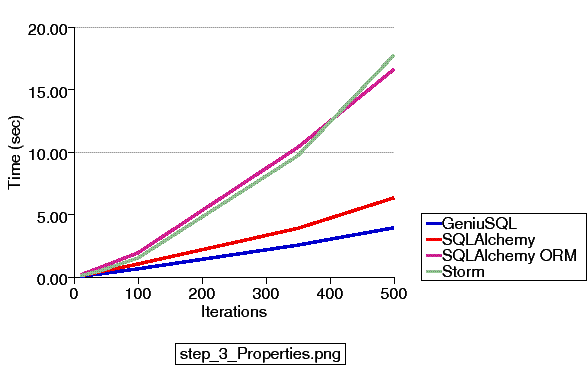
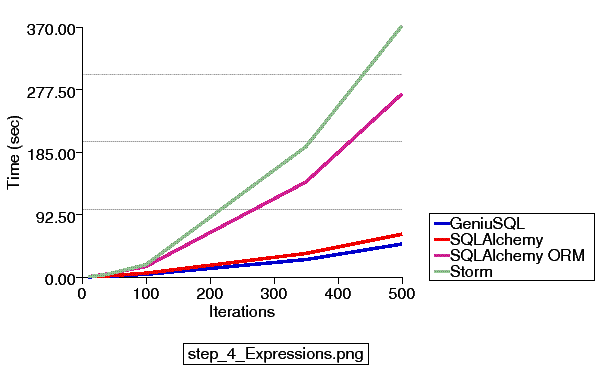
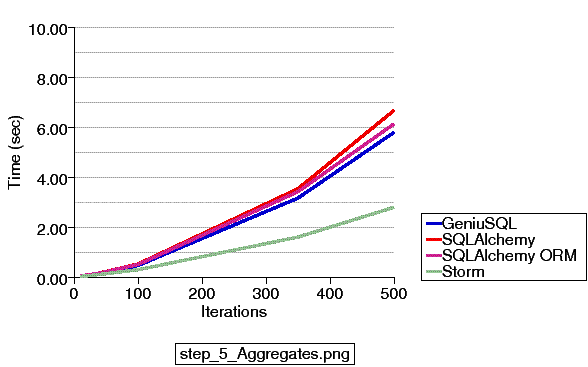
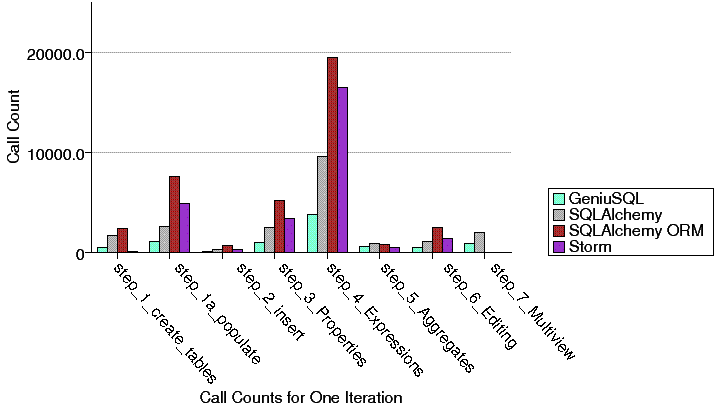
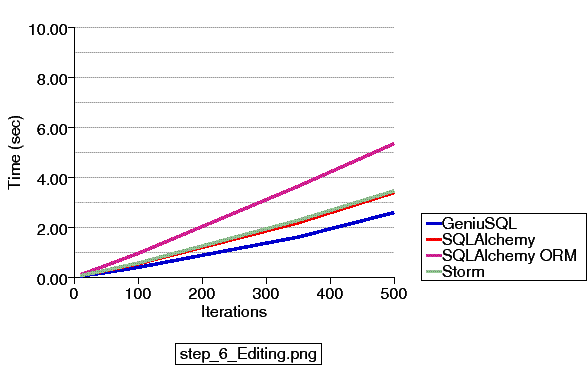
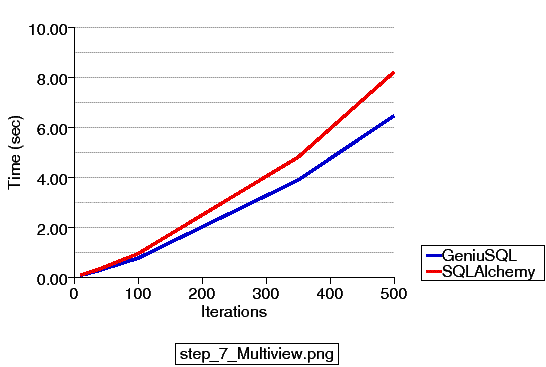
Updated 4/25/2011 - A new series of examples are committed to the 0.7 branch which illustrate
several ways of associating a particular related object with multiple parents - these are
modern examples which are based on Declarative and Declarative Mixins. One of these scripts,
an updated polymorphic association example, can be found at the bottom of this post.
The other day Ben Bangert pointed me over
to Understanding Polymorphic Associations,
a method used by ActiveRecord to
allow a certain type of object to be associated with multiple
kinds of parent object, along with the question "Can SQLAlchemy
do this?".
My initial mental reaction when I hear "can SQLAlchemy do XYZ"
is "probably", with the hopes that it isn't going to require a
total refactoring of internals to make it happen. In this case,
it took me awhile to figure out exactly what AR is getting at in
this one, since my own cognitive dissonance was being heavily
influenced by the meaning of "polymorphic" in SA terminology. In
SA, the word "polymorphic" is usually meant to mean "a mapper
that loads instances across a class hierarchy in one query".
This means if you have a mapper for class Vehicle, and
inheriting mappers for Car, Train and Airplane, you can
load a list of Car, Train, and Airplane objects from just
one Query call (typically via a UNION ALL statement...but
some new twists to that idea are coming up in SA 0.4).
The "polymorphic association", on the other hand, while it bears
some resemblance to the regular polymorphic union of a class
hierarchy, its not really the same since you're only dealing
with a particular association to a single target class from any
number of source classes, source classes which don't have
anything else to do with each other; i.e. they aren't in any
particular inheritance relationship and probably are all
persisted in completely different tables. In this way, the
polymorphic association has a lot less to do with object
inheritance and a lot more to do with aspect oriented
programming (AOP); a particular concept needs to be applied to a
divergent set of entities which otherwise are not directly
related. Such a concept is referred to as a cross cutting
concern, such as, all the entities in your domain need to
support a history log of all changes to a common logging table.
In the AR example, an Order and a User object are
illustrated to both require links to an Address object.
While studying AR's example, the primary thing I was looking for
was not the various keywords and directives used to express the
object relationship in Ruby, instead I was looking for how the
database tables are laid out. Once I found that, the exact
nature of the relationship would immediately become apparent.
This is one thing I like about SQL; it cuts through all the
abstracted mumbo jumbo and just shows you the raw relationships
in the most plain spoken way possible. Like virtually every ORM
I've ever looked at, I could see AR's docs were no exception in
that they were long on configurational/usage patterns and very
brief on illustrating actual SQL. SQLAlchemy is the only ORM I
know of, for any platform, which does not take the position of
SQL as an "implementation detail". It takes the position that
the developer wants to deal with domain objects as well as
SQL/relational concepts at equal levels. Does this violate
abstraction and/or encapsulation ? Not at all, SQLAlchemy isn't
in the business of building an opaque abstraction layer for you.
Its just providing the richest zone of overlap between the two
idioms as it possibly can so that you can build the
best abstraction for your needs.
So I found AR's primary table for its users/orders/addresses
example to be the addresses table. This is mostly a regular
looking table, with some extra columns added to create the
association. Lets illustrate the AR example piece by piece by
building a copy of it in SA. We'll start with just the concrete
tables and relationships and worry about generalizing a feature
out of it later.
We'll start with the standard SQLAlchemy boilerplate for SA
examples...import the whole namespace in just to save typing,
set up an anonymous connection to an in-memory sqlite database:
from sqlalchemy import *
metadata = BoundMetaData('sqlite://', echo=False)
Next lets look at their addresses table (I added a surrogate
key because I think AR is actually going to put one there):
addresses = Table("addresses", metadata,
Column('id', Integer, primary_key=True),
Column('addressable_id', Integer),
Column('addressable_type', String(50)),
Column('street', String(100)),
Column('city', String(50)),
Column('country', String(50))
)
A totally normal address table, except for the combination of
the addressable_id and addressable_type columns. Normally,
you'd see a column such as user_id or customer_id with an
explicit foreign key constraint to a table like users or
customers, so that any number of address rows can be
associated to that particular referenced table. But here,
addressable_id has no foreign key whatsoever. In this example,
that's intentional. It's because many different "source" tables
can conceivably be referenced by addressable_id against their
surrogate primary key column. From this, it follows that if more
than one source table has the same primary key value, its
ambiguous which of those tables is referenced by a particular
addressable_id value. Therefore, the addressable_type column
qualifies <em>which</em> of those tables we should be looking
at. Such as, if two tables users and orders both wanted to
reference rows in addresses, you'd get this:
users: user_id name
-----------------
1 bob
2 ed
orders: order_id description
-------------------------
1 order #1
5 order #2
addresses: id addressable_id addressable_type street
----------------------------------------------------------------------
1 1 'user' 123 anywhere street
2 1 'user' 345 orchard ave
3 2 'user' 27 fulton st.
4 1 'order' 444 park ave.
The first three rows of addresses have an addressable_id
which references rows in users, the last row has an
addressable_id which references a row in orders. So to get
all the address rows that are mapped to user id 1, you'd say:
select * from addresses where addressable_id=1 and addressable_type='user'
If you didn't have the extra criterion for addressable_type,
you'd also get address id 4, which is related to an order, not a
user.
As a side note, I've been noticing that AR doesn't even support
foreign keys out of the box, instead requiring a plugin in order
to deal with them. People say this is due to AR's history as a
MySQL-oriented ORM, and as we all know MySQL for many years
tried to convince us all that foreign keys were silly. Well they
lost that argument and its too bad AR is still trying to make
it, but whatever. Even though this schema requires a
relationship with an explicit "no FK constraint" in order to
function, I'm going to make a guess that AR's history as a
non-FK oriented tool is what led to the adoption of patterns
like this in the first place.
Well, your DBA will never take you seriously again, but lets go
with it (for now). The "join" condition implied by the "user"
query above is:
addressable_id=<associated id>; AND addressable_type=<string identifier>
So that we may start constructing SQL expressions the SQLAlchemy
way, lets write out the users and orders tables:
users = Table("users", metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50), nullable=False)
)
orders = Table("orders", metadata,
Column('id', Integer, primary_key=True),
Column('description', String(50), nullable=False)
)
Each table has a surrogate primary key and just one column of
actual data for example's sake. Placeholder classes for both
entities:
class User(object):
pass
class Order(object):
pass
From what we've seen so far, it wont be possible for an
Address object to exist without having both an
addressable_type and an addressable_id attribute. SQLAlchemy
takes care of "foreign key" relationships (even though we don't
yet have a real "foreign key" set up), but lets add the "type"
attribute to the constructor since we know we'll have to
populate that ourselves:
class Address(object):
def __init__(self, type):
self.addressable_type = type
Next, we know we're going to have a little bit of code-intensive
stuff to set up the relationship to both User and Order (and
whatever else), including making it look as much like the AR
example as possible, so lets set up a function addressable
which will do the work of the "addressable interface". In this
function, we want to have the ability to mark a class as
"addressable" using either a one-to-one or one-to-many
(many-to-many is of course totally doable, but that would
require a slightly different table setup, so we aren't
addressing that here). We also want to define the
create_address() method on the source class which will both
create a new Address object as well as properly associate it
with the parent instance, and we want to be able to fetch the
parent instance given an Address object, so we will need some
backref (bi-directional relationship) action in there too.
Additionally, our table has no foreign key constraints on it yet
we need to set up a relationship. This will have to be expressed
manually. We can generically define the join condition between
any table and the addresses table via:
primaryjoin = and_(
list(table.primary_key)[0] == addresses.c.addressable_id,
addresses.c.addressable_type == table.name
)
Above, we are using the primary_key attribute of the source
table, converted from an unordered set to a list and pulling the
sole column from that list, to get at the single primary key
column of the source table (we are assuming a single-column
primary key for source tables, since thats all that
addressable_id can handle referencing to). The second part of
the criterion relates the addressable_type column to the
string name of the table. We're using that only because its a
string name that happens to be conveniently available;
substitute other naming schemes according to taste.
The full function then looks like:
def addressable(cls, name, uselist=True):
"""addressable 'interface'."""
def create_address(self):
a = Address(table.name)
if uselist:
getattr(self, name).append(a)
else:
setattr(self, name, a)
return a
cls.create_address = create_address
mapper = class_mapper(cls)
table = mapper.local_table
# no constraints. therefore define constraints in an ad-hoc fashion.
primaryjoin = and_(
list(table.primary_key)[0] == addresses.c.addressable_id,
addresses.c.addressable_type == table.name
)
foreign_keys = [addresses.c.addressable_id]
mapper.add_property(name, relation(
Address,
primaryjoin=primaryjoin, uselist=uselist, foreign_keys=foreign_keys,
backref=backref(
'_backref_%s' % table.name,
primaryjoin=list(table.primary_key)[0] == addresses.c.addressable_id,
foreign_keys=foreign_keys
)
)
)
The addressable function is given the source class, the name
under which the Address-referencing scalar or collection
attribute should be placed, and the uselist flag indicating if
we are doing one-to-one or one-to-many. The first thing it does
is create a create_address() function which is attached to the
source class as an instance method; when invoked, this method
will instantiate an Address with its proper type string and
associate it with the parent using the scalar or list semantics
specified. We then retrieve the Mapper and Table associated
with the source class and set up a new relation() relating the
source class directly to the Address class, and add it to the
source mapper using the desired attribute name. We also set up a
backref which has a more unusual name given to it.
Both the forward and backwards refs use a constructed primary
join condition and an explicit "foreign key" column. How can we
say theres a foreign key involved ? The tables themselves have
no FKs whatsoever. Well, turns out that mappers and relations
don't really care if there are any actual FKs defined for the
tables (or if its even impossible to define any, as is the
case here). They only care what columns you'd like to
<em>pretend</em> have a foreign key constraint for the purposes
of this relationship, if there aren't any for real (or even if
there are). So in all cases, each relation added to a source
class' mapper should consider the addressable_id column to be
the "foreign key" column, at least as far as the relationship
between a particular source row and address row is concerned.
The same goes for the backwards reference which is essentially
identical except its looked at from the reverse direction.
Let's look at the backref. First of all, its join condition is
lacking the comparison to the addressable_type column. While
it still works if the comparison is present, its not actually
needed in the case of the backreference since it's invoked from
the perspective of a row in the addresses table, and it
actually gets in the way of the backref's lazy loader optimizing
its reverse-load for a parent User or Order already present in
the session. I certainly didn't guess this ahead of time, I only
know it because I tried with the full condition to start with,
and I watched the SQL generated as I ran my test program (this
notion of experimenting and observing to see what works was the
inspiration behind the word "alchemy", BTW, just don't blow up
your kitchen).
The backref itself has a name which is derived from the source
table name. This implies that after several source classes have
had addressable applied to them, Address will have several
mapped properties of the form _backref_<name>, such as:
# get an address
someaddress = session.query(Address).get(5)
# see if it has an associated Order object
order = someaddress._backref_orders
# see if it has an associated User object
user = someaddress._backref_users
Thats a pretty unpleasant interface above. We actually don't
have to guess what kind of object an Address is related to,
because it already has an addressable_type attribute. Lets
redefine the Address class with a handy property that will
give us the correct associated source instance:
class Address(object):
def __init__(self, type):
self.addressable_type = type
member = property(lambda self: getattr(self, '_backref_%s' % self.addressable_type))
mapper(Address, addresses)
And that, adding in a simple mapper def for Address is it...as
far as our addressable interface. One hardwired version of a
polymorphic association creator. Lets create mappers for User
and Order and use our new toy:
mapper(User, users)
addressable(User, 'addresses', uselist=True)
mapper(Order, orders)
addressable(Order, 'address', uselist=False)
Notice that we didn't do the usual properties={} thing when
setting up the Address relation, as the addressable function
calls add_property() on the source mapper for us. This is
because we needed the attribute name to set up our
create_address() method as well, and we only want to have to
type the concrete attribute name once. Its not quite as nice as
AR's minimalist syntax, but its a custom job at this point; in a
couple of weeks someone will probably stick this feature into
Elixir and it'll be just as pleasing all over again. Plus we're
not done with it yet anyway.
So everything is set up; lets fire it up:
and create a session and manipulate some objects (note to any AR
users reading this: before you cringe at the verbosity of using
Session and Query objects [not to mention the whole Table
and mapper() dichotomy], it should be noted that both SA as
well as Elixir provide myriad ways of creating more succinct
code than this...we are showing "raw SA" here, which while it's
the most verbose is also the most explicit and flexible, and is
also the style everyone knows):
u1 = User()
u1.name = 'bob'
o1 = Order()
o1.description = 'order 1'
a1 = u1.create_address()
a1.street = '123 anywhere street'
a2 = u1.create_address()
a2.street = '345 orchard ave'
a3 = o1.create_address()
a3.street = '444 park ave.'
sess = create_session()
sess.save(u1)
sess.save(o1)
sess.flush()
sess.clear()
# query objects, get their addresses
bob = sess.query(User).get_by(name='bob')
assert [s.street for s in bob.addresses] == ['123 anywhere street', '345 orchard ave']
order = sess.query(Order).get_by(description='order 1')
assert order.address.street == '444 park ave.'
# query from Address to members
for address in sess.query(Address).list():
print "Street", address.street, "Member", address.member
Running the application without SQL logging gives us the output:
Street 123 anywhere street Member <__main__.User object at 0x11e3750>
Street 345 orchard ave Member <__main__.User object at 0x11e3750>
Street 444 park ave. Member <__main__.Order object at 0x11e3b10>
And so ends Part I, how to mimic AR's exact method of
"polymorphic association". It still feels a little empty knowing
that it violates normalization. Or if not, take my word for
it...you won't impress Yahoo's development team with this
schema. Which brings us to the lightning round:
Part II. How to Really Do This.
It shouldn't be too hard to generalize out the addressable
function we created above to provide the
polymorphic-association-feature-ala-ActiveRecord as a pluggable
module. Before we do that, lets fix the foreign key constraint
issue. The AR article has a comment suggesting that, "Well, if
you really need a constraint, put a trigger". Which again, is a
little naive as to the full functionality of a foreign key
(CASCADE, anyone?). In our case, we are going to "flip around"
some aspects of the relationship such that the addresses table
will be a totally normal table, and each source table will
instead have a foreign key column referencing the association.
How will we do that, and still allow one-to-many relationships ?
By doing what the name "association" implies - adding an
association table. This new table will express part of what
we're currently trying to express between just two tables.
For those following at home, the script re-begins right
underneath the BoundMetaData declaration, with all new tables.
First, the association table:
address_associations = Table("address_associations", metadata,
Column('assoc_id', Integer, primary_key=True),
Column('type', String(50), nullable=False)
)
In this table, the association itself becomes an entity of its
own with its own primary key, as well as a type column which
will serve a similar, but less intrusive, purpose as the
previous addressable_type column. For the one-to-one and
one-to-many use cases we are currently addressing, the
addresses table can be expressed as o2m from this association
table (as before, for a many-to-many association, yet another
table is needed, which we won't go into in this article):
addresses = Table("addresses", metadata,
Column('id', Integer, primary_key=True),
Column('assoc_id', None, ForeignKey('address_associations.assoc_id')),
Column('street', String(100)),
Column('city', String(50)),
Column('country', String(50))
)
Back into familiar territory, where a table relation can have a
foreign key. Note the lesser known trick we are using of
defining the type as None for a column which has a foreign
key; the resulting type will be taken from the referenced
column. Now, when defining orders and users tables, they
will take on the burden of expressing relationships to this
association, by having the foreign key on their side:
users = Table("users", metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50), nullable=False),
Column('assoc_id', None, ForeignKey('address_associations.assoc_id'))
)
orders = Table("orders", metadata,
Column('id', Integer, primary_key=True),
Column('description', String(50), nullable=False),
Column('assoc_id', None, ForeignKey('address_associations.assoc_id'))
)
This puts the "polymorphism" where it should be; on the part of
the schema that is actually polymorphic. Lets see what our
sample data looks like with this scheme:
users: user_id name assoc_id
----------------------------
1 bob 1
2 ed 2
orders: order_id description assoc_id
------------------------------------
1 order #1 3
5 order #2 NULL
address_associations: assoc_id type
------------------
1 'user'
2 'user'
3 'order'
addresses: id assoc_id street
-----------------------------------------
1 1 123 anywhere street
2 1 345 orchard ave
3 2 27 fulton st.
4 3 444 park ave.
So the above data shows that the addresses table loses its
previously complex role. As an additional advantage, the
limitation that all source tables (i.e. users and orders tables)
need have a single-column surrogate primary key goes away as
well (see how it all falls together when you follow the rules?)
Keen users might notice another interesting facet of this
schema: which is that the relation from address_associations
to the users and orders table is identical to a
<strong>joined table inheritance</strong> pattern, where users
and orders both <em>inherit</em> from address_associations
(save for the NULL value for order #2, for which we could have a
placeholder row in address_associations). Suddenly, the
original premise that AR's "polymorphic associations" are
nothing like SA's "polymorphic inheritance" starts to melt away.
It's not that they're so different, its just how AR was doing it
made it look less like the traditional inheritance pattern.
In fact, while this table scheme is exactly joined table
inheritance, and we could certainly go the "straight" route of
creating an Addressable base class and mapper from which the
User and Order classes/mappers derive, then creating the
traditional SA "polymorphic mapping" using UNION ALL (or
whatever surprise 0.4 has in store) with a relationship to
Address, here we're going to do it differently. Namely,
because we are still going to look at this association as a
"cross-cutting concern" rather than an "is-a" relationship, and
also because SA's explicit inheritance features only support
single inheritance, and we'd rather not occupy the "inherits"
slot with a relationship that is at best a mixin, not an "is-a".
So lets define a new class AddressAssoc which we can use to
map to the address_associations table, and a new addressable
function to replace the old one. This function will apply a
little bit more Python property magic in order to create
collection- or scalar-based property on the source class which
completely conceals the usage of AddressAssoc:
class AddressAssoc(object):
def __init__(self, name):
self.type = name
def addressable(cls, name, uselist=True):
"""addressable 'interface'."""
mapper = class_mapper(cls)
table = mapper.local_table
mapper.add_property('address_rel', relation(AddressAssoc, backref=backref('_backref_%s' % table.name, uselist=False)))
if uselist:
# list based property decorator
def get(self):
if self.address_rel is None:
self.address_rel = AddressAssoc(table.name)
return self.address_rel.addresses
setattr(cls, name, property(get))
else:
# scalar based property decorator
def get(self):
return self.address_rel.addresses[0]
def set(self, value):
if self.address_rel is None:
self.address_rel = AddressAssoc(table.name)
self.address_rel.addresses = [value]
setattr(cls, name, property(get, set))
The basic idea of the relationship is exactly the same as
before; we will be adding distinct backrefs to the
AddressAssoc object for each kind of relation configured. But
observe that now that we're back in normalized constraint-land,
the relationship is totally simple and requires no explicit
joins or ad-hoc foreign key arguments. The "database" part of
this operation is now just one line of code, and the rest is
just some property-based "make-it-pretty" code to make usage
more convenient. While the property code is a little verbose,
overall the whole thing is conceptually simpler.
The member property on Address looks just about the same as
before, save for that its pulling the backref off of its
association object rather than itself, as defined below along
with the mappers for Address and AddressAssoc:
class Address(object):
member = property(lambda self: getattr(self.association, '_backref_%s' % self.association.type))
mapper(Address, addresses)
mapper(AddressAssoc, address_associations, properties={
'addresses':relation(Address, backref='association'),
})
The Address object is now freely creatable with no weird
create_address() function needed (although we probably could
have found a way to do away with it in the first example too).
Lets do the same test code, minus the usage of
create_address(), which of course we could add back in if we
wanted it that way. Otherwise, the test is exactly the same, and
the results are the same:
class User(object):
pass
mapper(User, users)
addressable(User, 'addresses', uselist=True)
class Order(object):
pass
mapper(Order, orders)
addressable(Order, 'address', uselist=False)
metadata.create_all()
u1 = User()
u1.name = 'bob'
o1 = Order()
o1.description = 'order 1'
a1 = Address()
u1.addresses.append(a1)
a1.street = '123 anywhere street'
a2 = Address()
u1.addresses.append(a2)
a2.street = '345 orchard ave'
o1.address = Address()
o1.address.street = '444 park ave.'
sess = create_session()
sess.save(u1)
sess.save(o1)
sess.flush()
sess.clear()
# query objects, get their addresses
bob = sess.query(User).get_by(name='bob')
assert [s.street for s in bob.addresses] == ['123 anywhere street', '345 orchard ave']
order = sess.query(Order).get_by(description='order 1')
assert order.address.street == '444 park ave.'
# query from Address to members
for address in sess.query(Address).list():
print "Street", address.street, "Member", address.member
Output is again:
Street 123 anywhere street Member <__main__.User object at 0x11fb050>
Street 345 orchard ave Member <__main__.User object at 0x11fb050>
Street 444 park ave. Member <__main__.Order object at 0x11f3110>
And there you have it, polymorphic associations, SQLAlchemy
style.
Both of these examples, as well as a third version that
"genericizes" the address function, are checked into the
/examples directory of SQLAlchemy.
poly_assoc_1.py - AR
version.
poly_assoc_2.py -
Normalized version.
poly_assoc_3.py - Generic
version.
discriminator_on_association.py - New in 0.7 !
Modernized declarative form of polymorphic association.